
Deep Dive: Data Center Networking
From micro to macro - how the next generation AI data centers are built from the ground up; discussing networking equipment, AI training clusters, and the Ethernet

A few weeks ago, we examined the global optical module market. In this post today, I want to take a closer look at the broader infrastructure of AI data centers, discussing other key components that form the network, and more importantly, how they work in unison to form structures and systems that eventually enable the next generation AI training and inference. We will also analyze key public companies operating in the space and identify potential winners based on the evolving AI trend.
The article will follow a micro-to-macro structure. We’ll begin by examining the individual components that make up data center networks. Next, we'll explore how these components come together to create highly coordinated clusters (such as NVDA's NVL72 and NVL36 racks) for more efficient AI training and inference. Lastly, we'll focus on the broader DC network, highlighting the transition from InfiniBand (IB) to Ethernet and its potential implications.
Let’s get started.
Part 1: Micro - Key components in data center networks
The key components that facilitate data transmissions within data centers include switches, optical modules, Network Interface Cards (NICs), cables (both copper and fiber), as well as interface standards (such as PCIe and NVLink). Each serves specific purposes, but working together to enable seamless transmission and exchange of data between critical computing and storage units in the data center.
1. PCIe (Peripheral Component Interconnect Express)
When data needs to flow from a GPU to other parts of the internal system (the motherboard) and vice versa, it must first conform to an interface standard. This interface governs how the data is formatted, transmitted, and received, addressing key parameters such as transmission bandwidth, latency, and power efficiency. This ensures compatibility with other components in the system. One of the most widely used interface standards is PCIe, now in its sixth generation, PCIe 5.0, released in 2022.
Due to its 1) point-to-point architecture (dedicated communication paths instead of the shared bus design of older standards), 2) multi-lane setup (compared to single-lane setup for older standards), and 3) backward compatibility (meaning it’s compatible with older standards), PCIe delivers higher bandwidth, lower latency, reduced power consumption, and greater scalability compared to previous standards like PCI and AGP.
Here’s how it works from an architectural viewpoint: GPUs are inserted into PCIe slots on the motherboard, where data flows through the PCIe bus to connect with CPUs, storage devices, and network cards within the internal system. Leading producers of PCIe switches include Broadcom ($AVGO) and Microchip ($MCHP).
2. NVLinks
Although PCIe provides significant improvement over older interface standards, it has shown notable limitations in bandwidth and latency for high-performance computing (HPC), AI workloads, and GPU-to-GPU communication. To address the challenges, NVDA introduced its proprietary interface, NVLink, in 2016, specifically for GPU-to-GPU connections. Now in its fifth generation, NVLink offers advantages over PCIe, including: 1) much higher higher bandwidth; 2) lower latency; 3) higher power efficiency; and 4) unified memory access (which enables GPUs to access each other’s memory directly, improving data sharing efficiency).
The reason that NVLink achieves significantly higher bandwidth is that it can encompass more channels, even though the bandwidth per channel is comparable to PCIe. It's like NVLink is a highway with dozens of lanes, while PCIe is limited to just a few. Because NVLink is developed for NVDA’s in-house, closed systems, the company has the flexibility to design the optimal number of channels to meet its needs. In contrast, PCIe, as an open and standardized interface, must adhere to stricter protocols to maintain compatibility with a much wider range of devices, limiting its ability to freely scale channel counts. The latest NVLink 5.0 delivers a bidirectional GPU-to-GPU interconnect bandwidth of 1.8 TB/s, which is more than 14 times the bandwidth of PCIe Gen-5, per NVDA’s official website.
From an architectural perspective, NVLink-supported GPUs are equipped with NVLink ports. These ports do not connect to the motherboard, but instead connect directly to other GPUs via cables. These connections play a critical role in NVDA’s upcoming NVL72 and NVL36 racks, which we will discuss further later.
Despite its impressive capabilities, NVLink remains exclusive to NVDA. As a result, other companies have been collaborating to develop alternative interfaces that could achieve comparable throughput for AI workloads. However, no significant progress has been reported thus far.
3. Network Interface Cards (NICs)
Once data is transmitted internally via PCIe to the motherboard, it can interact with CPUs, storage/ memory units, and other GPUs on the same motherboard through the PCIe bus. However, if the data needs to be transmitted outside the system (with "system" referring to setups like the NVL72 or NVL36 racks, as we will discuss later), it must pass through a Network Interface Card (NIC). NICs handle the crucial task of converting the data from the system's internal format into a format compatible with external networks, such as InfiniBand (IB) or Ethernet. This process involves adapting the data to the appropriate network protocols to ensure transmission compatibility.
Therefore, the difference between NICs and interface standards lies in their scope. Interface standards are designed for communication between internal components within a system. However, these standards cannot facilitate connection to external networks - this is where NICs come in. In the context of IB, NICs are also sometimes referred to as Host Channel Adapters (HCAs).
A widely used NIC model in modern data centers is the ConnectX-8 (CX8), which is compatible with both IB and Ethernet networks and supports bandwidths of 400/800 Gbps. For AI training workloads, a typical GPU-to-NIC configuration ratio is 1:1.
4. Optical Modules
For long-distance data transmission, both within and outside the system, optical modules are essential. These modules are typically plugged into NICs (for transmitting signals outside the system), NVLink ports (for GPU-to-GPU connections typically within the system), or switches. Data is transmitted via fiber optic cables, which connect to optical modules on the receiving end for signal conversion and processing.
Optical modules function by converting electrical signals into optical signals (and vice versa), ensuring fast and efficient data transfer with high throughput and minimal signal loss. I’ve covered the global optical modules market in great detail in a previous post. I highly recommend you checking it out and reading in conjunction with this article for a more comprehensive understanding of the entire data center network infrastructure.
5. Cables (Copper)
The optical modules + fiber cable combo is usually for long-distance transmission. However, for short-distance communications, copper wires are often a more cost-effective solution. For instance, in NVL72 and NVL36 racks, a type of copper wires (ACC, which will be discussed later) are used to connect directly to NVLink ports on GPUs, supporting high-speed GPU-to-GPU communication.
There are three main types of copper wires used in data centers:
DAC (Direct Attach Copper): are passive copper cables. Since they don’t have built-in chips to amplify, compensate, or adjust signals, their effective transmission distance is limited. At 100 Gbps speed, their range is typically around 1 meter and maximum 2 meters, which restricts their usability in today’s increasingly complex data center systems
ACC (Active Copper Cable): are active cables that integrate EQ chips on both ends of a DAC. The EQ chips compensate for signal losses, increasing the effective transmission distance. At 100 Gbps, ACCs can transmit effectively over 3-4 meters, while for 200 Gbps, the range is 2-3 meters. This makes ACCs an excellent choice for connections within NVDA’s NVL72 rack or between adjacent racks
AEC (Active Electrical Cables): are also active cables; they are essentially ACCs adding DSPs at both ends of the cable. Due to the DSP functionality, AECs can not only amply signals but also optimize and reshape signals, further enhancing their effective transmission distances: at 100 Gbps, AECs reliably support transmission over distances of 5-10 meters, while at 200 Gbps, they can achieve transmission of around 3 meters, and in some cases, even 5 meters. Additionally, the inclusion of DSPs enables AECs to provide superior signal compatibility between devices from different vendors, making them an ideal for versatile and complex networking environments. However, the downside of the AEC solution is its higher cost, increased latency, greater power consumption, and larger physical size.
6. Switches
So far, we’ve explored how data flows from point to point. However, for a network to function seamlessly, a device is needed to manage and direct data traffic efficiently and reliably. This is where switches come into play.
Switches serve as central hubs. They manage and prioritize data flow to ensure efficient communication and prevent transmission bottlenecks.For instance, data can travel from one NIC through cables to a switch, which then routes it to an NIC of another server, completing a cross-server data transmission.
In the case of NVLink, NVSwitches are used to enable interconnection among multiple GPUs. The NVSwitch chip is essentially the same as NVDA’s IB switch chip in terms of functional specs, with the key difference being the protocols they use: NVLink or IB.
Switch itself is a BIG topic, I’ve decided to devote an entire (separate) post next to discuss it in greater detail. Stay tuned!
Part 2: Meso - Constructing AI training & inference clusters
Having covered the key individual components of data center networks, let’s now explore how companies like NVDA integrate these elements into systems optimized for AI training efficiency.
To grasp this, we need to first understand how AI models are trained from a hardware perspective. Overall, training LLMs involves dividing and processing the model using three main approaches: tensor parallelism, pipeline parallelism, and model parallelism.
Tensor Parallelism: involves performing calculations within the same layer or adjacent layers of the model in a cluster of highly-connected GPUs. For instance, a 96-layer model can be split into 48 groups, with each comprising two adjacent layers and being processed by a closely-knit cluster of 8 GPUs. Data exchanges within the cluster occur with minimal latency (~200 nanoseconds), ensuring highest efficiency processing of the high-priority calculations
Pipeline Parallelism: involves allocating different layer groups to multiple clusters, and communicating weights and gradient information through forward and backward propagation. A training dataset needs to flow sequentially from the first layer to the last layer and then propagate back to the first to complete one training cycle; thus, close coordination between clusters is also essential
Model Parallelism: involves distributing complete copies of the model across larger clusters to train on different datasets, and then combine each’s results by averaging their gradients periodically. This enables parallel training of the model
The most intensive data exchanges clearly occur during tensor parallelism and pipeline parallelism. Therefore, a key approach to achieve higher AI training efficiency is to construct systems that can handle these two types of parallelism within a highly interconnected, highly efficient environment. NVDA’s upcoming NVL72 and NVL36 racks, equipped with the latest-generation GB200 superchips, are prime examples of this approach.
NVL72
NVL72 is a high-performance computing system developed by NVDA, designed to enhance AI training and inference capabilities. It integrates 72 Blackwell GPUs (B200) and 36 Grace CPUs within a single rack, interconnected via NVDA's fifth-generation NVLink technology. This configuration enables efficient handling of large-scale AI models.
Architecture-wise, the rack is composed of 9 switch trays, each housing an NVSwitch, and 18 compute trays, each containing two GB200 superchips. Each GB200 integrates two B200 GPUs and one Grace CPU, resulting in a total of 72 B200 GPUs per rack (hence the name NVL72). The system employs liquid cooling for thermal management and utilizes PCIe 6.0 for external network communications. A diagram from Semianalysis provides an excellent visualization of the rack's structure:
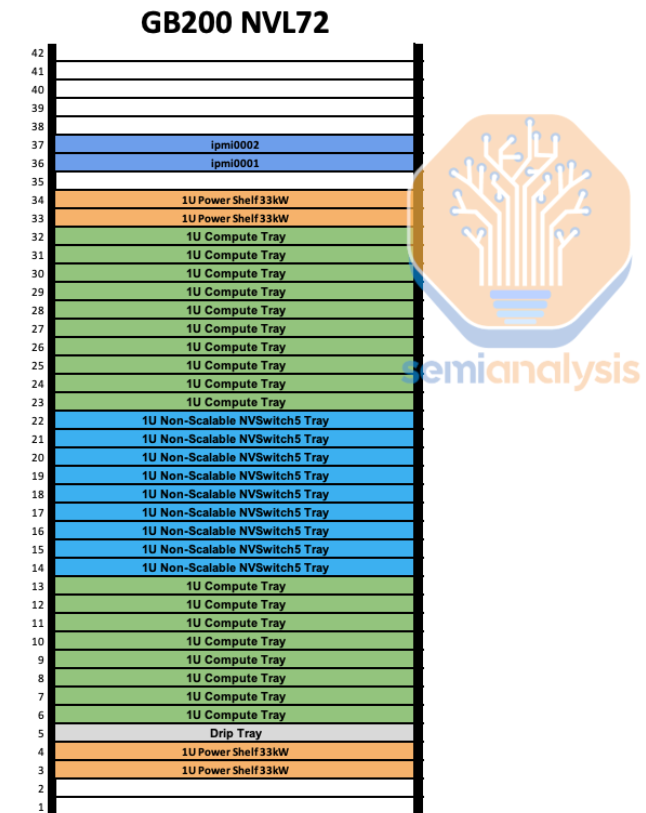
To drill down further, each B200 GPU comes with 18 communication lanes, each providing 100GB/s of bandwidth, thus totaling a bidirectional bandwidth of 1.8 TB/s per GPU. According to NVDA, this GPU-to-GPU throughput is more than 14 times the bandwidth of PCIe Gen-5. To interconnect these NVLink-enabled GPUs, the system employs NVSwitches, each equipped with 144 NVLink ports operating @100 GB/s, allowing full connectivity to all 8 GPUs in the block - the calculation is 8 GPUs * 18 lanes @100GB/s per GPU = 144 lanes @100GB/s per switch. With 9 total switches in the rack, the system delivers a combined bidirectional bandwidth of c.127 TB/s.
The rack also employs c.5,000 ACCs to establish the NVLink connections between GPUs and between GPUs and NVSwitches. Each GPU lane is paired with 4 ACCs, therefore in total there are 4 ACCs * 18 lanes per GPU * 72 GPUs = 5,184 ACCs.
You might wonder, “in your previous analysis, AECs support longer distance and greater compatibility, Why did NVDA choose ACCs instead for the rack interconnection?” There are a few major considerations: 1) Cost: AECs are expensive due to the inclusion of two DSPs, which are priced similarly to those used in optical modules; an 800G AEC cable costs around $500 - multiples higher than an equivalent ACC. 2) Power consumption: each DSP in an AEC consumes 500-800mW/ channel, compared to 300mW/ channel for EQ. 3) Latency: one DSP adds 100-200 nanoseconds of latency to the cable, compared to just 1-2 nanoseconds for an EQ chip. 4) Physical size: AECs have a larger diameter than ACC, making them less suitable for high-density structures such as the NVL72. 5) Reduced importance on Compatibility: NVDA's racks operate within a controlled, proprietary environment where all protocols and devices are in-house; this makes ACC’s main weakness - compatibility - less of a problem for this use case.
Each ACC contains 8 EQ chips - 4 on each end - critical for amplifying signals and reducing signal loss in ACC transmissions. While not overly complex to make, achieving high ACC performance requires precise design and production controls to minimize signal distortion during amplification. Currently, Macom ($MTSI) exclusively supplies the EQ chips for 1.6T ACCs used in NVDA's NVL72/36 racks, though additional vendors may enter in the future.
I know - it’s a lot of math! However, understanding these numbers is essential for investors to accurately assess the potential value created by the ongoing NVL deployments.
NVL36
The NVL72 is an incredibly complex system, hailed by some industry experts as an “engineering marvel.” Currently, challenges remain in its engineering, with some heat dissipation and space optimization issues identified during testing that could delay its deployment. To address a wider range of needs, NVDA also offers a simpler version - the NVL36. This rack includes 9 switch trays and 9 compute trays (each housing 4 B200 GPUs), for a total of 36 GPUs. NVL36 is well-suited for clients seeking high-performance computing within tighter space, power, or budget constraints.
NVL576
However, even the NVL72 is not the pinnacle of the latest-generation NVLink capabilities - the maximum number of fully connected GPUs in a closed system is 576, represented by the NVL576 system. This configuration employs a two-layer structure:
Layer 1: Consists of 288 NV switches distributed across 16 switch planes, each managing one NVL36 rack. With each NVL36 rack housing 36 B200 GPUs, and each GPU featuring 18 lanes @100GB/s throughput, the total throughput per NVL36 rack is 648 lanes @100GB/s (calculated as 18 lanes per GPU × 36 GPUs); this is managed by one switch plane comprising 18 NV switches. In total, across the 16 switch planes, Layer 1 provides a total downward connection of 10,368 lanes @100GB/s (calculated as 648 lanes per plane × 16 planes). However, this layer only facilitates full connectivity among the 36 GPUs within the same NVL36 rack and does not interconnect GPUs of the other 15 NVL36 racks, necessitating a second layer of switches to achieve full connectivity
Layer 2: To achieve full connectivity, the 10,368 100GB/s lanes of downward connection in L1 must be matched by an equal number of upward lanes, meaning each L1 switch also allocates 36 lanes @100GB/s facing upward. These lanes then connect to switches in L2, which requires half as many switches - 144 in total - since they only need to handle downward connections. Each L2 switch manages 72 lanes @100GB/s, and connects to all 576 GPUs through connecting to all 16 switch planes in L1, ultimately realizing full interconnectivity
Semianalysis again has a great visual representation of the rack structure:

The NVL576 system is incredibly powerful, capable of training models with trillions or even tens of trillions of parameters (for context, GPT-4 is estimated to have c.1.8 trillion parameters). Then, why isn’t NVL576 the go-to architect for all future AI training, and why is NVDA primarily promoting NVL36 and NVL72 instead?
The key issue is cost - particularly related to optical modules. In NVL576, optical modules are necessary to connect L1 and L2 - the physical distance between the two layers exceeds the effective range of copper wires. The number of 1.6T optical modules required is 9 times the number of B200 GPUs. For a rough cost estimate: a B200 GPU costs c.$30-40K, while one 1.6T optical module will cost c.$1,500 according to my previous post on the optical module market:
“As for 1.6T modules, initial mass production is expected in Q4 2024, with an estimated starting price of around $2,000. However, as production scales up, the price is expected to drop to ~$1,500 next year.”
This means that 9 modules cost c.$14K, nearly half the cost of the GPU itself! This substantially raises the overall cost of the system, making NVL576 economically much less desirable at this stage. Technological breakthroughs in optical transmission are needed to reduce costs of the solution and make it more economically viable in the future.
Part 3: Macro - Beyond NVL72 & trending toward Ethernet
The Clos topology
For large models, a single NVL72 rack is not enough to handle the entire training, requiring a larger structure to facilitate the process. One popularly adopted topology is the Clos architecture. In this configuration, switches, each equipped with 144 ports in an IB setup, operate at 100 GB/s (or 800 Gbps) to match the 800 Gbps bandwidth of the NICs connected to each B200 GPU within NVL72 racks. Thus, with 72 switches, the setup can connect up to 144 NVL72 racks, with each switch linking to 2 racks/ 144 GPUs. This elegantly designed system enables the interconnection of over 10,000 GPUs (144 racks × 72 GPUs per rack = 10,368 GPUs).
However, it’s important to note that these 10,000 GPUs are not all fully connected to each other like the 72 GPUs within an NVL72 rack. Each GPU has a single 800 Gbps connection to an external switch for exchange with GPUs in the other 143 racks. In this configuration, tensor parallelism and likely pipeline parallelism occur within each NVL72 rack, utilizing NVLink for high-speed, low-latency communication; yet model parallelism operates across racks, facilitated by the Clos network and interconnected switches. The structure strikes a balance between scalability and performance, making it well-suited for training massive AI models.
The Clos structure can even go beyond one layer to offer even larger cluster size. The two-layer Clos architecture enables clusters with over 100K GPUs. Here’s how the topology works:
First layer (leaf): Each set still consists of 72 switches with 144 ports, but connecting to 72 NVL72 racks below, reserving half of the switch ports for upward connections to the second layer. There are 36 same sets in the first layer, resulting in a total of 2,592 IB switches
Second layer (spine): Requires only half as many switches, totaling 1,296, because they only need to connect downward to L1.
Combined, the architecture requires 3,888 switches (2,592 + 1,296), supporting up to 187K GPUs (calculated as 72 GPUs per rack * 72 racks per set * 36 sets). This structure is designed for super-large-scale AI training.
Infiniband (IB)
From a broader macro perspective, the Clos architecture and similar designs can function in either IB or Ethernet environments. IB is a high-performance networking protocol optimized for AI and HPC workloads. It mainly relies on NVDA's in-house networking ecosystem (incl. switches, cables, NICs, software stacks…) since NVDA’s acquisition of Mellanox in 2020. Its key strengths are high throughput, ultra-low latency, and efficient scalability, while it also comes with higher power consumption and elevated costs. Thus, IB is best suited for high-demand, high-stake, time-critical AI training tasks, which have indeed been the mainstream over the past 2 years as companies raced to build large-scale AI data centers to compete in the frontier LLM landscape.
Ethernet
However, as model inference grows to play a larger and larger role in data center operations, and Ethernet solutions continue to evolve to narrow the performance gap with IB, Ethernet is becoming an increasingly prominent presence in AI infrastructures. Ethernet offers several compelling advantages compared to IB: 1) higher compatibility: Ethernet is widely supported and integrates easily across different systems; 2) cost efficiency: Ethernet can be up to 60% cheaper than IB, offering significant cost savings for large-scale deployments; 3) lower power consumption: Ethernet typically requires less power than IB, contributing to more energy-efficient operations.
You can think of IB as Apple’s iOS - efficient and premium, but closed and expensive - while Ethernet resembles the Android ecosystem, offering greater openness and compatibility. Ethernet’s openness and compatibility make it particularly appealing for AI inference tasks, where systems need to frequently exchange information with external networks.
Ethernet is not without its challenges. The first one is packet loss: when buffer capacity is exceeded, packets are dropped, resulting in unrecoverable data loss - a big problem for AI training. IB, in contrast, inherently doesn’t have such an issue because it employs a credit-based flow control system, which ensures that the sender only transmits data when the receiver has sufficient buffer space. This mechanism prevents buffer overflow, effectively eliminating the risk of packet loss.
Another drawback is relatively lower transmission speed. In Ethernet, data must be formatted into packets before transmission and then unpacked upon arrival. This process adds latency, resulting in an average point-to-point latency of c.600 nanoseconds for Ethernet, compared to c.200 nanoseconds for IB. (However, this limitation is less critical for inference tasks, which are generally less sensitive to latency.)
The Ethernet ecosystem has been actively working to enhance efficiency, including the development of RoCE (RDMA over Converged Ethernet) protocol, which aims to bring the benefits of Remote Direct Memory Access (RDMA) - a technology native to IB - to Ethernet networks. RDMA enables direct memory-to-memory info exchange between GPUs without involving the CPU or operating system. This minimizes data copying and reduces chances of delays/ error that could lead to packet loss. In contrast, traditional Ethernet networks require data to be first packaged, and then be transferred to the other GPU to be parsed and written into memory, introducing complexity, delays and higher risks of errors.
So far, RoCE has evolved through two versions: v1 and v2. While v1 was limited, v2 introduced meaningful enhancements, especially in congestion management. However, some challenges remain. Firstly, the RoCE standard remains somewhat loosely defined, which can sometimes result in compatibility issues between RoCE-compliant devices from different vendors. Additionally, network performance can be less reliable in more complex setups.
Currently, Ethernet represents c.60-70% of the switch market value in data center networks, while IB makes up the remainder. The growth of IB has been largely driven up by the rapid expansion of AI training infrastructure in 2023 & 24. However, Ethernet’s share is expected to turn around and increase. Companies like GOOG and META are actively testing Ethernet-based AI networks using RDMA-supported switches, reporting positive results so far. NVDA’s Spectrum Ethernet switches also have been sampled to ODMs, with mass production anticipated for late 2024/ early 2025. Notably, companies are also exploring the use of Ethernet for training workloads, with testing of such solutions since 2H 2024. CSPs, having historically invested heavily in Ethernet infrastructure, are highly motivated to expand its usage for its greater compatibility and cost advantages.
I hold a positive outlook on Ethernet's growth trajectory for 2025 and beyond. Its continued advancement is expected to create new opportunities for players in its ecosystem, which will be explored in the following section.
In the paid section below, we will dive into the key public company players across three subsegments discussed earlier, analyzing how these companies stack against each other. This analysis is valuable for readers seeking to understand the stock implications of developments and advancements in data center networks.
Names covered in this section include:
Nvidia ($NVDA)
Macom ($MTSI)
Marvell ($MRVL)
Broadcom ($AVGO)
Intel ($INTC)
Amphenol ($APH)
TE Connectivity ($TEL)
Luxshare (SZ: 002475)
